In this blog post, I’ll give a bite-sized summary of our paper Learning to Plan for Language Modeling from Unlabeled Data, which was accepted at COLM 2024 🥳.
Problem Setting
Language Models (LMs) have revolutionized various NLP tasks, largely due to their self-supervised pretraining objectives that scale effectively with data. However, traditional LMs predict the next word in a sequence purely left-to-right, which contrasts with how humans approach writing complex texts. We typically plan ahead, coming up with ideas at an abstract level before putting them into words.
Our research aimed to bridge this gap by developing a planner that can generate abstract writing plans. These plans have two key features:
- Scalability through self-supervision: Like modern LMs, the planner can learn from large amounts of unlabeled data.
- Expressiveness by operating in a latent space: Instead of planning in text space, which can be restrictive, our planner operates in a more expressive latent space.
Approach
Our approach is divided into three main components, as illustrated below:
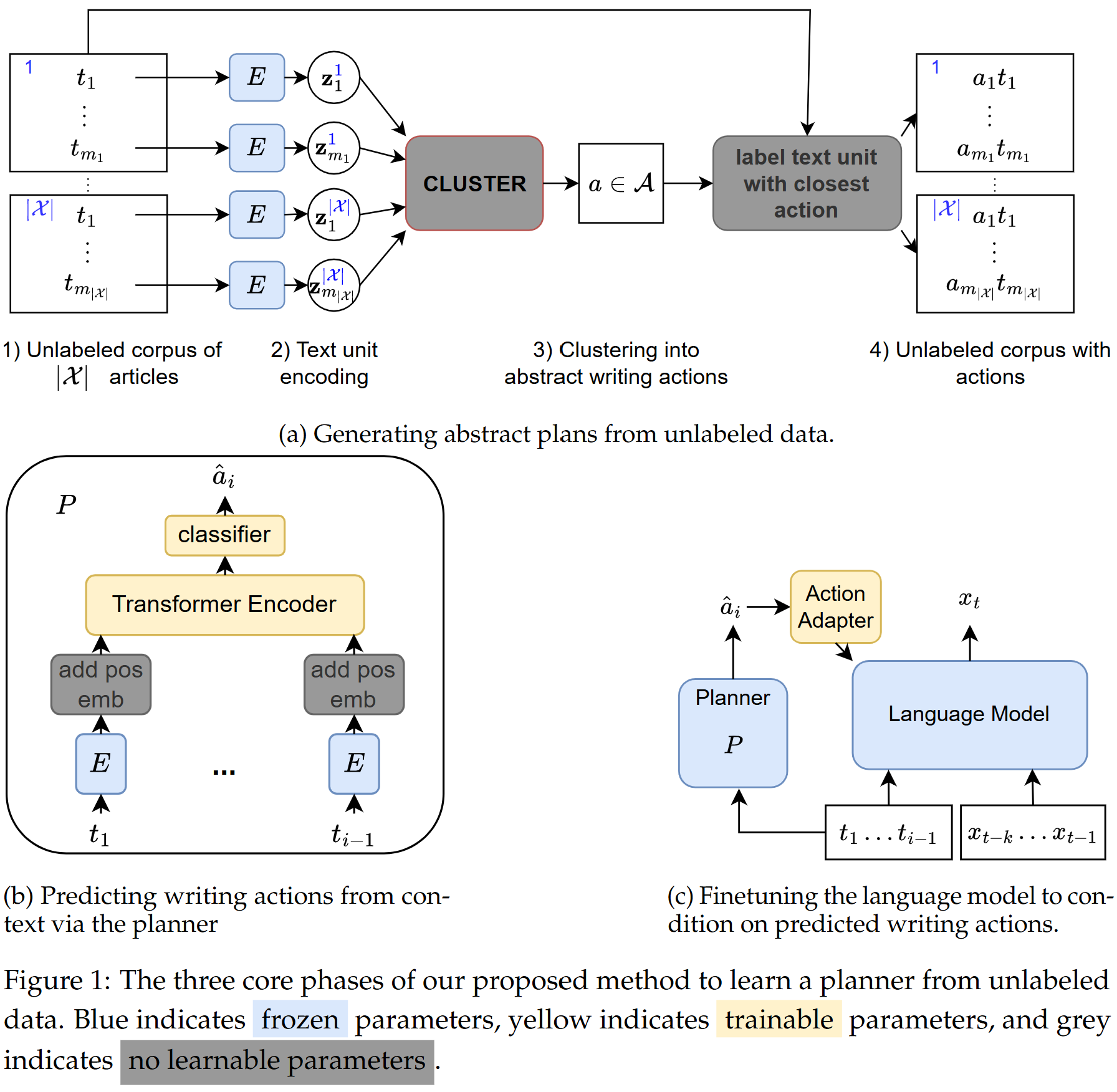
We start by generating sentence embeddings and then clustering these embeddings to define a set of ‘writing actions’. These actions serve as the building blocks for abstract writing plans.
Next, we train a planner to predict the next writing action based on the preceding text. Our experiments showed that a planner that first processes within-sentence context to create sentence embeddings and then operates across sentences performed the best.
Finally, we integrate the predicted writing actions into the language model. We explored two training variants:
- Oracle actions: Using ground-truth actions, knowing this could introduce a train/test mismatch.
- Predicted actions: Using the planner’s predicted actions, which are less precise but avoid the mismatch.
Results
Evaluation Metrics
We assessed our approach using several metrics:
- Perplexity: The standard metric for evaluating LMs, reflecting how well the model predicts the next word.
- Surface-level generation metrics: ROUGE-2 (measuring n-gram overlap with reference text) and MAUVE (comparing distribution of generated versus reference text).
- Abstract-level generation metrics: We converted both reference and generated text into sequences of high-level writing actions and compared these using Edit distance and Latent Perplexity.
Key Findings
Our primary goal was to determine whether the language model could benefit from the planner’s predictions. Here’s what we discovered:
- Improved Performance: Our models consistently outperformed the baseline (which used fixed, uninformative actions) in both perplexity and generation metrics.
- Perplexity Benefits: Training the LM on predicted actions led to better perplexity scores, likely due to the absence of train/test mismatch.
- Enhanced Plan-Following: Training on oracle actions increased the likelihood that the LM would “follow its own plan,” with around 40% alignment compared to 20% when using predicted actions.
- Generation Quality: Despite worse perplexity, models trained on oracle actions sometimes performed better on generation metrics than model trained on predicted actions, likely due to stronger plan-following. This suggests that fine-tuning LMs to minimize train/test mismatch while maintaining plan fidelity is a promising direction for future research.
What Now?
While our findings are encouraging, our planner might not take the world by storm just yet. For one, it currently only planw one step ahead. Extending this to multi-step planning could open the door to leveraging search algorithms during text generation. Additionally, tailoring planner-predicted actions to specific LMs could further enhance performance. There’s plenty of exciting work ahead!
For a deeper dive, check out our full paper at https://arxiv.org/pdf/2404.00614. hugo